# --- Configuration --- AUTH_EMAIL=""# Optional: Older API key method API_TOKEN=""# !!! 必须修改: Your Cloudflare API Token !!! ZONE_ID=""# !!! 必须修改: Your Zone ID !!! RECORD_TYPE="A"# !!! 必须修改: Record type ("A" or "AAAA") !!! LOG_FILE=""# !!! 检查确认: Log file path and permissions !!! IP_CACHE_FILE=""# !!! 检查确认: Cache file path and permissions !!! SLEEP_BETWEEN_RECORDS=1 # Seconds to wait between processing records (0 to disable)
# !!! 必须修改: List of DNS records to update !!! RECORD_NAMES=( "baidu.com" "sb.baidu.com" # Add more records here... )
# Public IP lookup services (primary and backups) if [ "$RECORD_TYPE" == "A" ]; then IP_SERVICES=("https://api.ipify.org""https://icanhazip.com""https://ipinfo.io/ip") IP_TYPE_DESC="IPv4" elif [ "$RECORD_TYPE" == "AAAA" ]; then IP_SERVICES=("https://api64.ipify.org""https://icanhazip.com""https://ipinfo.io/ip") IP_TYPE_DESC="IPv6" else # Log initial config error to file if possible, otherwise echo err_msg="$(date '+%Y-%m-%d %H:%M:%S') - Error: Unsupported RECORD_TYPE: $RECORD_TYPE" if [ -n "$LOG_FILE" ] && [ -d "$(dirname "$LOG_FILE")" ] && [ -w "$(dirname "$LOG_FILE")" ]; then echo"$err_msg" >> "$LOG_FILE" else echo"$err_msg" fi exit 1 fi # --- End Configuration ---
# --- Helper function for logging --- log() { local message="$1" local log_entry="$(date '+%Y-%m-%d %H:%M:%S') - $message" # Try to log to file, fallback to echo if file/dir not writable or not set if [ -n "$LOG_FILE" ]; then if ! echo"$log_entry" >> "$LOG_FILE" 2>/dev/null; then echo"$log_entry (Error writing to log file: $LOG_FILE)" fi else echo"$log_entry" fi }
# --- Function to get current public IP with redundancy --- get_current_ip() { local ip="" for service in"${IP_SERVICES[@]}"; do log"Attempting to get public IP from $service..." ip=$(curl -s --connect-timeout 5 "$service") if [[ -n "$ip" && "$ip" =~ ^[0-9a-fA-F.:]+$ ]]; then log"Successfully retrieved IP: $ip from $service" echo"$ip" return 0 else log"Failed or received invalid response from $service (Response: $ip)" fi done log"Error: Could not retrieve current public IP from any service." return 1 }
# --- Main Logic ---
# 1. Get current public IP address CURRENT_IP=$(get_current_ip) if [ $? -ne 0 ]; then exit 1 fi log"Current public $IP_TYPE_DESC IP is: $CURRENT_IP"
# 2. Compare with cached IP CACHED_IP="" if [ -f "$IP_CACHE_FILE" ]; then CACHED_IP=$(cat"$IP_CACHE_FILE") log"Last known IP from cache ($IP_CACHE_FILE): $CACHED_IP" fi
if [ "$CURRENT_IP" == "$CACHED_IP" ]; then log"Public IP ($CURRENT_IP) matches cached IP. No Cloudflare update needed." exit 0 fi
log"Public IP ($CURRENT_IP) differs from cached IP ($CACHED_IP) or cache is empty. Proceeding with Cloudflare checks..."
# --- Loop through each record name --- log"Starting DNS update process for ${#RECORD_NAMES[@]} record(s)..." ALL_SUCCESS=true UPDATES_PERFORMED=false
for RECORD_NAME in"${RECORD_NAMES[@]}"; do log"--- Processing record: $RECORD_NAME ---"
# 3. Get the DNS Record ID, current IP, and **Proxied Status** for THIS record from Cloudflare RECORD_INFO=$(curl -s --connect-timeout 10 -X GET "https://api.cloudflare.com/client/v4/zones/$ZONE_ID/dns_records?type=$RECORD_TYPE&name=$RECORD_NAME" \ -H "Authorization: Bearer $API_TOKEN" \ -H "Content-Type: application/json")
RECORD_SUCCESS=$(echo"$RECORD_INFO" | jq -r '.success') if [ "$RECORD_SUCCESS" != "true" ]; then log"Error querying DNS record for '$RECORD_NAME'. API Response: $RECORD_INFO" ALL_SUCCESS=false continue fi
RECORD_COUNT=$(echo"$RECORD_INFO" | jq '.result | length') if [ "$RECORD_COUNT" -eq 0 ]; then log"Error: DNS record '$RECORD_NAME' ($RECORD_TYPE) not found. Skipping." ALL_SUCCESS=false continue fi if [ "$RECORD_COUNT" -gt 1 ]; then log"Warning: Multiple records found for '$RECORD_NAME' ($RECORD_TYPE). Using the first one." fi
# Validate all extracted values if [ -z "$RECORD_ID" ] || [ "$RECORD_ID" == "null" ] || \ [ -z "$RECORD_IP" ] || [ "$RECORD_IP" == "null" ] || \ [ -z "$RECORD_PROXIED_STATUS" ] || [ "$RECORD_PROXIED_STATUS" == "null" ]; then# <<< 添加: 验证代理状态 log"Error: Could not retrieve valid DNS Record ID, IP, or Proxied status for '$RECORD_NAME'. Response: $RECORD_INFO. Skipping." ALL_SUCCESS=false continue fi
log"Cloudflare DNS IP for $RECORD_NAME is: $RECORD_IP, Proxied: $RECORD_PROXIED_STATUS"# <<< 修改: 日志包含代理状态
# 4. Compare IPs and update THIS record if necessary, preserving proxied status if [ "$CURRENT_IP" != "$RECORD_IP" ]; then log"IP has changed for $RECORD_NAME ($RECORD_IP -> $CURRENT_IP). Updating Cloudflare DNS record..."
if [ "$UPDATE_SUCCESS" == "true" ]; then log"Successfully updated DNS record for $RECORD_NAME to $CURRENT_IP (Proxied status kept as $RECORD_PROXIED_STATUS)." UPDATES_PERFORMED=true else log"Error updating DNS record for $RECORD_NAME. API Response: $UPDATE_RESPONSE" ALL_SUCCESS=false fi else log"Cloudflare IP for $RECORD_NAME already matches current public IP ($CURRENT_IP). No update needed." fi
# Optional sleep between records if [ "$SLEEP_BETWEEN_RECORDS" -gt 0 ]; then log"Waiting ${SLEEP_BETWEEN_RECORDS}s before next record..." sleep"$SLEEP_BETWEEN_RECORDS" fi
done# --- End of loop for RECORD_NAMES ---
# 5. Update cache file if the process completed without critical errors preventing updates and IP changed # (We update cache even if some non-critical errors occurred for individual records, # as long as we successfully determined the new public IP differs from the old cache) if [ "$CURRENT_IP" != "$CACHED_IP" ]; then # Check if we should update the cache. We update if *any* update was attempted or if cache was initially empty. # We might choose *not* to update if ALL attempts failed, but let's update if the public IP genuinely changed. log"Updating IP cache file $IP_CACHE_FILE with new IP: $CURRENT_IP" echo"$CURRENT_IP" > "$IP_CACHE_FILE" # More conservative approach: only update cache if $ALL_SUCCESS is true AND $UPDATES_PERFORMED is true. # if $ALL_SUCCESS && $UPDATES_PERFORMED; then ... echo ... fi fi
log"Finished processing all records." if$ALL_SUCCESS; then exit 0 else log"One or more errors occurred during the update process. Check logs above." exit 1 fi
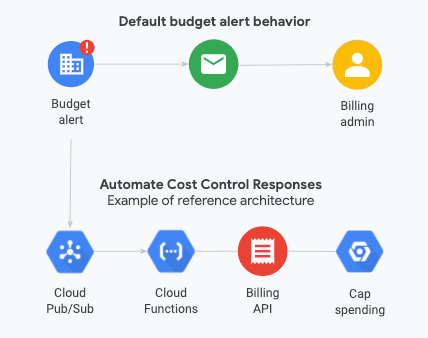
填入开头的变量,可遍历修改同个ID域的多个二级域名,其中会生成 log 文件,和 ip 缓存文件, ip 缓存文件用于比对 ip 免于频繁访问 API 触发风控。
进入 Pub/Sub 界面找到刚创建的主题,在主题的 更多操作 中触发 Cloud Run 函数,其中代码直接粘贴文档代码,不设置环境变量话,其中 PROJECT_ID 修改为你实际的项目 ID
Pub/Sub 主题中发布消息测试
走了一遍流程发现其中的难点在于权限
Pub/Sub 服务 (service-<PROJECT_NUMBER>@gcp-sa-pubsub.iam.gserviceaccount.com) 需要 Cloud Run Invoker 权限来触发/调用你的函数
函数需要调用 Billing API 的权限: 当你的函数代码运行时,去调用 Cloud Billing API 来执行停用结算的操作。
要解决上面两个问题,在创建 Cloud run Function 时,直接用默认的Compute Engine default service account 为 触发器服务账号(默认),运行时服务账号 需要在 IAM 中新建,并授予其 Billing Account Administrator 角色